华为逻辑折叠深度解读:当摩尔定律跑不动时,我们还能做什么?
 Alfxjx
Alfxjx这是一篇关于华为在ISCAS 2026上发布的"韬定律"(τ-Scaling)和"逻辑折叠"(Logic Folding)技术的深度长文。全文约2万字,涵盖技术原理、工程难点、产业链影响以及半导体行业基础知识扫盲。
引言:一条没有EUV的突围路线
2026年5月,华为在ISCAS(国际电路与系统会议)上扔出了一套新理论——韬定律(τ-Scaling),顺便还带了一项叫"逻辑折叠"(Logic Folding)的芯片架构技术。
科技圈很快炸了锅。大家最想问的是:没有EUV光刻机,被卡着脖子,华为怎么还能让芯片性能往上走?
这篇文章试着回答这个问题,以及围绕它产生的一系列延伸问题:逻辑折叠到底是什么?它和AMD的X3D有什么区别?工程上有哪些坑?
如果你对半导体是外行,别担心,文末有个"小白扫盲",用盖房子的比喻帮你快速理解芯片设计、制造、封测和设备之间的关系。
好,从头说起。
一、背景:摩尔定律跑不动了
要理解华为做了什么,首先要理解它面临的问题。
传统的摩尔定律,本质上是"几何缩微"——把晶体管做得越来越小,在同样面积里塞进更多,性能就上去了。但这个路子现在遇到了大问题:
- 晶体管已经小到接近物理极限,再缩小漏电、发热都压不住
- 最先进的EUV光刻机被禁运,华为拿不到
- 麒麟9030 Pro(2025年)之后,华为发现自己的手机芯片进入了"性能饱和区"
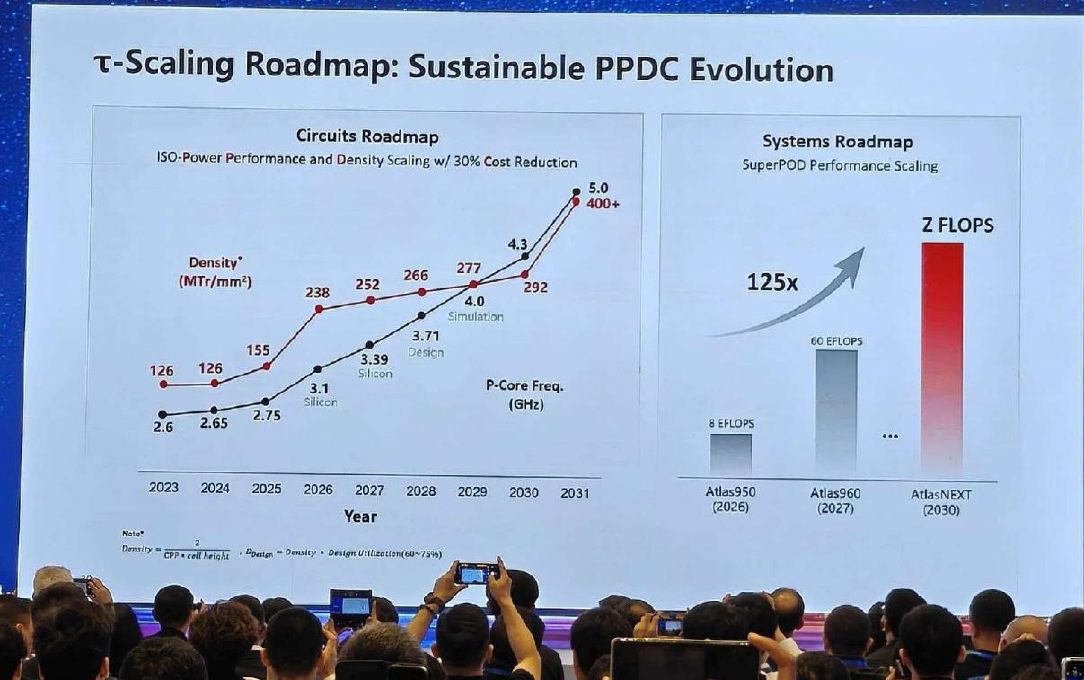
2023年到2025年,华为的晶体管密度几乎停滞在126 MTr/mm²(大约对应台积电N7/N6水平),频率也只在2.6GHz到2.75GHz之间原地踏步。
这不是华为一家的问题。2005年左右,Dennard缩放定律就已经失效了。这个定律说的是:晶体管缩小,电压等比降低,功耗密度保持不变。失效之后,虽然摩尔定律还在走,但单位面积的功耗密度开始上升。
这就引出了一个更残酷的概念——"暗硅"。
什么是暗硅?
2009年,加州大学伯克利分校的Michael Taylor团队首次提出了这个概念。
暗硅,就是芯片上永远无法同时点亮的晶体管。
Dennard定律失效后,晶体管继续缩小,但电压没法再跟着降了。到3nm节点,超过99%的晶体管在任何时刻都得关着——不然热量会把芯片烧穿。
| 制程节点 | 可同时激活的晶体管比例 | 暗硅比例 |
|---|---|---|
| 45nm | ~20% | 80% |
| 28nm | ~10% | 90% |
| 14nm | ~5% | 95% |
| 7nm | ~2% | 98% |
| 3nm | <1% | >99% |
芯片设计师们的应对策略包括多核架构、DVFS动态调频调压、时钟门控、异构计算、专用加速器等。但这些本质上都是"权宜之计"——有晶体管,但不能用。
华为的处境更艰难。台积电可以继续做3nm、2nm,而华为被限制在7nm级别。如果找不到新的突破口,产品性能就会被竞争对手远远甩开。
二、华为的"换道"思路:从"摊煎饼"变"盖楼房"
华为给出的答案是:韬定律 + 逻辑折叠。
韬定律的核心
何庭波在论文中提出了一个观点:
摩尔定律本质上从来就不是关于几何的。更小的晶体管提升性能,是因为它们开关更快;更密的互连提升性能,是因为信号传输距离更短。空间缩微只是压缩时间的工具。
一旦认识到这一点,一个自然的重新框架就出现了:把时间本身作为优化的首要指标。
τ-Scaling的核心是——用"时间缩微"替代"几何缩微"。
传统芯片设计像摊煎饼,所有计算单元都平铺在硅片的二维平面上。信号要从A点传到B点,得在平面上跑很长的距离,这个传播时间就叫"时延"。以前缩短时延只能靠晶体管做小、排更密。
华为的逻辑折叠技术,思路是把"平房改楼房":不改变晶体管本身的大小,而是把原本平铺的逻辑计算单元垂直堆叠成两层甚至多层,中间通过TSV(硅通孔)技术打通。
这样,原本需要水平跑几百微米的信号路径,现在可以垂直"跳楼"几微米就到达。
就像城市从横向扩张变成建摩天大楼,地还是那块地,但能装的东西多了很多,而且楼内坐电梯比路上开车快得多。
跟AMD的X3D堆叠有什么不同?
AMD的X3D技术(比如锐龙7 9800X3D)也是3D堆叠,但它是在处理器上堆缓存(存储),相对简单。
华为的逻辑折叠是堆叠逻辑计算单元本身——也就是真正做运算的部分。技术难度和工程挑战都要大得多。业内形容是"两块芯片粘在一起,但粘的是大脑,不是仓库"。
| 对比项 | AMD X3D(存储叠逻辑) | 华为逻辑折叠(逻辑叠逻辑) |
|---|---|---|
| 发热密度 | 中等(只有CPU发热) | 极高(双层发热) |
| 时钟同步 | 相对简单 | 极度复杂 |
| 供电设计 | 中等 | 复杂 |
| TSV密度 | 较高 | 极高 |
| 散热路径 | 较直接 | 严重受阻 |
三、麒麟2026的实际数据
这是逻辑折叠的首次商业化落地(2026年秋季发布,可能由Mate 90系列首发)。
| 指标 | 数据 |
|---|---|
| 晶体管密度 | 238 MTr/mm²(比传统2D设计提升53.5%) |
| P核峰值频率 | 3.1 GHz(首次突破3GHz,比上代提升12.7%) |
| P核能效 | 提升41% |
| 工艺节点 | 仍基于成熟制程(7nm级别),不依赖EUV |
作为对比:
- 台积电N4(4nm):170-190 MTr/mm²
- 台积电N3(3nm):270-290 MTr/mm²
- 三星3nm:150-190 MTr/mm²
麒麟2026的238 MTr/mm²,介于台积电4nm和3nm之间。加上华为自己的架构设计优化,实际体验有望接近台积电3nm水平。
用户能感知到什么?
- 手机更快更流畅:CPU首次突破3GHz,日常应用、游戏、多任务处理都会有明显提升
- 发热和续航改善:能效提升41%,同样性能下更省电,发热更低
- AI能力增强:芯片算力密度提升,端侧AI响应更快
路线图
- 2026年:238 MTr/mm²,3.1GHz(保守起步,只针对关键路径做折叠)
- 2027年:已进入Silicon验证阶段
- 2031年:400+ MTr/mm²,5.0GHz(等效台积电1.4nm水平)
何庭波的原话是:"我们的解决方案走得通,走得远。"
四、工程实现有哪些难题?
逻辑折叠在工程上被称为"比AMD X3D更难",根本原因在于:存储不发热,逻辑会发热。当两块"发热的大脑"直接贴在一起,工程难度呈几何级数上升。
1. 散热:头等难题
这是逻辑折叠与存储堆叠最根本的区别。
| 堆叠类型 | 发热情况 | 散热路径 |
|---|---|---|
| AMD X3D(存储堆叠) | CPU发热,缓存几乎不发热 | 逻辑层贴散热器,散热自然 |
| 华为逻辑折叠 | 两层逻辑都在发热 | 底层的热量要穿过上层才能出去,形成"蒸笼效应" |
具体难点:
- 功率密度翻倍:两层逻辑芯片堆叠后,单位面积的功耗密度可能增加1.5-2倍,热点温度可达120°C以上,远超常规芯片的85°C安全线
- 热耦合:上层芯片的热量会加热下层,下层又反作用于上层,形成正反馈热循环
- TSV散热通道有限:虽然TSV本身能导热,但数量受信号走线约束,无法无限增加
- 微凸块/混合键合层是热瓶颈:键合界面导热系数远低于硅本身
华为可能的应对:只叠关键路径、热TSV导通、微流道液冷、让两层核心错峰跑。
2. 信号完整性与时钟同步
逻辑芯片的运算单元之间需要纳秒级甚至皮秒级的精确同步,这比存储芯片的读写操作苛刻得多。
问题的本质:3D堆叠打破了芯片内部信号传输路径的物理连续性和环境统一性。信号每穿过一次TSV/键合界面,都会发生反射、延迟和畸变;两层芯片处于不同的温度、电压和应力环境中,时钟"心跳"无法天然对齐。
- 时钟树跨层:时钟信号要均匀同步到两层芯片上的所有触发器,任何skew都会直接导致计算错误
- 信号串扰:TSV穿透硅片时,会在周围晶体管上引入应力场,改变其电学特性
- 时序收敛:传统EDA工具假设所有门都在一个平面上,现在需要在三维空间内做时序分析和优化
- 接口协议:两层逻辑之间需要全新的片上互连协议,带宽、延迟、功耗都要重新权衡
为什么AMD X3D没有这个问题?
AMD的X3D是在CPU上面堆缓存。缓存有几个好特性:不自带时钟、功耗极低、接口简单。而华为的逻辑折叠是两层逻辑单元堆在一起,两层都在主动计算,都有自己的时钟网络,都在发热。两层之间需要实时数据交互。这就从"一个大脑指挥一个仓库"变成了"两个大脑必须同步思考"——难度天壤之别。
3. 供电网络:IR压降问题
给两层逻辑芯片稳定供电,就像给高楼供水——楼层越高,水压越低。
- IR Drop累积:电流穿过TSV、微凸块、键合层,每一层都有电阻,累积的电压降可能导致底层芯片供电不足
- 电源噪声耦合:两层逻辑同时开关时,电源网络上的噪声会相互耦合
- 去耦电容部署:需要在有限的三维空间内布置足够的去耦电容来平滑电源噪声
4. 热机械可靠性与良率
- 热膨胀系数失配:硅、铜、氧化层、键合材料在热胀冷缩时形变不同,反复热循环后会产生应力集中,导致微凸块开裂或分层
- 晶圆翘曲:超薄硅片在TSV刻蚀、键合后极易弯曲,影响后续对准
- 良率指数级衰减:如果是wafer-to-wafer(W2W)键合,只要一层有一个缺陷点,整个堆叠就报废。两层都95%良率的wafer,W2W堆叠后良率可能只剩90%,且无法做已知良品挑选
五、生产和封测的系统性挑战
逻辑折叠从晶圆到成品,需要经过TSV制造、晶圆减薄、键合封装、量测检测、测试验证五大环节。
1. TSV制造:在硅片上打"电梯井"
TSV(硅通孔)是3D堆叠的"垂直电梯",制造过程极为棘手:
| 工艺步骤 | 核心问题 | 后果 |
|---|---|---|
| 深孔刻蚀 | 高深宽比的垂直孔难以保持侧壁光滑 | 侧壁粗糙导致铜填充出现空洞 |
| 绝缘层沉积 | 孔内绝缘层覆盖不均匀 | 漏电、击穿电压降低 |
| 铜填充 | 高深宽比孔内铜沉积容易出现空洞 | 电阻增大、可靠性下降 |
| CMP平坦化 | 铜垫的碟形凹陷和介电层侵蚀 | 键合界面不平整 |
| 背面露头 | 减薄后TSV背面露头的对准精度 | 与上层Die的互连对位不准 |
2. 晶圆减薄:把"厚砖块"变成"薄纸"
要将775μm厚的晶圆减薄到100μm甚至50μm:
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 机械强度骤降 | 50μm硅片如同"薄玻璃",极易碎裂 | 临时键合/解键合技术 |
| 晶圆翘曲 | TSV铜与硅的热膨胀系数失配导致弯曲 | 翘曲补偿载台、低应力临时键合胶 |
| TSV应力释放 | 减薄后TSV周围的应力集中导致裂纹 | 优化TSV尺寸/间距、应力缓冲材料 |
| TTV控制 | 整片晶圆厚度不均匀性 | 高精度研磨设备,TTV控制在1μm以内 |
3. 混合键合:3D堆叠的"圣杯"
华为逻辑折叠大概率采用面对面混合键合,即Cu-Cu金属直连加SiO2-SiO2熔合。
主要挑战包括:表面平整度要求铜垫与介电层的高度差小于1nm;清洁度要求超净间环境;对准精度要求W2W小于50nm;退火温度需要250-350°C;热膨胀系数失配需要在退火冷却过程中加以控制。
4. W2W vs D2W:路线选择
| 维度 | W2W(晶圆对晶圆) | D2W(芯片对晶圆) |
|---|---|---|
| 吞吐量 | 高(整片wafer一次键合) | 低(逐个die放置) |
| 对准精度 | <50nm | ~200nm |
| KGD筛选 | 无法筛选 | 可预先筛选Known Good Die |
| Die尺寸 | 必须相同 | 可不同(异构集成) |
| 成本模型 | 小die便宜,大die良率灾难 | 大die更有优势 |
如果麒麟2026的上下两层die尺寸相同且良率较高,W2W是成本优选;如果良率不够高,W2W的复合良率惩罚是致命的。D2W虽然慢,但可以只堆好die,避免浪费昂贵的logic die。
5. 良率管理:数学噩梦
3D堆叠的良率不是加法,是乘法:
$$Y_{total} = Y_{die1} \times Y_{die2} \times Y_{bonding} \times Y_{TSV}$$
假设单层逻辑die良率90%,键合良率95%,TSV良率99%,则最终良率 = 0.90 × 0.90 × 0.95 × 0.99 = 76%。这意味着24%的产品直接报废。
半导体行业的铁律——"十倍法则":缺陷发现得越晚,修正成本增加十倍。在3D堆叠中,一旦键合完成,几乎无法返工。
6. 测试验证
传统2D芯片所有I/O都在表面,探针可以直接接触。3D堆叠芯片中间层的I/O被埋在内部,无法物理接触。
解决方案包括:IEEE 1838标准定义3D IC的测试访问架构;BIST在每层die内嵌入自测试电路;分阶段测试(键合前、键合中、键合后、老化测试);片上温度/电压传感器实时监控运行状态;TSV冗余设计;X射线/超声波非破坏性检测。
六、产业链与国产替代
核心设备
逻辑折叠需要一条后摩尔时代的高端产线,核心设备如下:
TSV刻蚀设备
| 厂商 | 国家 | 核心产品 |
|---|---|---|
| Lam Research | 美国 | 全球CCP刻蚀龙头,市占率40-45% |
| Applied Materials | 美国 | 全系列刻蚀覆盖 |
| TEL | 日本 | ICP刻蚀技术领先,市占率30-35% |
| 中微公司 | 中国 | PrimoTSV深孔硅刻蚀设备,已量产 |
| 北方华创 | 中国 | PSE V300系列12英寸深硅刻蚀设备 |
CMP设备
这是混合键合成功的决定性环节。
| 厂商 | 国家 | 核心产品 |
|---|---|---|
| Applied Materials | 美国 | Reflexion系列,全球市占率约70% |
| Ebara | 日本 | 全球市占率约25% |
| 华海清科 | 中国 | 国内唯一12英寸CMP商业机型制造商 |
晶圆键合设备
| 厂商 | 国家 | 核心产品 |
|---|---|---|
| BESI | 荷兰 | 混合键合设备全球市占率约70% |
| EV Group | 奥地利 | W2W键合、D2W键合设备 |
| 拓荆科技 | 中国 | 国内混合键合设备领先 |
晶圆减薄与处理设备
DISCO是全球绝对龙头,主笼罩片机、研磨机、抛光机。迈为股份是国产替代DISCO的核心标的。
关键材料
CMP抛光垫主要由Dow、Cabot供应,国内有鼎龙股份。临时键合胶有Brewer Science、3M,国内有鼎龙股份、飞凯材料。TSV铜电镀液有Atotech、Dow,国内有上海新阳、天承科技。
散热材料
液态金属TIM
湖南中材盛特是国家专精特新企业,液金导热系数超70W/m·K,是苹果、索尼、富士康的供应商。江苏镓铟新材料专注半导体封装用高纯镓铟合金。苏州泰吉诺专做高端TIM,液金导热片Fil-LMS8000为铟基合金。
石墨烯导热膜
常州富烯科技产能90万㎡/年,是华为、荣耀核心供应商。深瑞墨烯(贝特瑞子公司)产能60万㎡/年,服务华为、OPPO、一加、realme。
七、何庭波论文深度解读
何庭波的论文题为《A Time Scaling Theory for Multi-Layer Electronic Systems》,2026年5月25日提交至中国科学院科技论文预发布平台。
核心命题
论文梳理了半导体行业"契约"的崩塌过程:
| 时间 | 事件 | 后果 |
|---|---|---|
| ~2005年 | Dennard缩放定律失效 | 电压无法随尺寸等比降低,"暗硅"时代开始 |
| 7nm以后 | 几何缩微回报递减 | 速度饱和;2nm节点单芯片设计预算超10亿美元 |
最关键的一句:"For organizations whose access to the most advanced lithography is constrained, the constraint became binding earlier and bears down more severely."
τ-Scaling的数学框架
$$\tau = f(\tau_{transistor}, \tau_{circuit}, \tau_{chip}, \tau_{system})$$
| 层级 | 时间尺度 | 优化手段 |
|---|---|---|
| 晶体管 | 皮秒 | 迁移率增强、应变工程、GAA |
| 电路 | 纳秒 | 低电阻导体、低κ介质、垂直集成缩短线长 |
| 芯片 | 微秒 | 架构选择、流水线深度、存储层次 |
| 系统 | 毫秒~秒 | 互连拓扑、协议栈、总线设计 |
代际缩放规则:$\tau_{t+1} = \frac{\tau_t}{\alpha}$
其中α是应用特定的缩放因子:
- 功耗受限移动设备:α ≈ 1.3×/年
- 安全关键型自动驾驶系统:α ≈ 1.5×/年
- AI工作负载:α 高达 10×/年
LogicFolding的技术细节
"LogicFolding is a design methodology that partitions digital, analog, and memory circuits across vertically stacked active tiers to jointly optimize performance, power, and area following the time scaling principle."
关键工艺参数(论文中首次披露):
| 参数 | 数值 | 含义 |
|---|---|---|
| Hybrid-bonding pitch | 1.5μm | 混合键合间距 |
| Overlay accuracy | <0.5μm | 对准精度 |
| TSV CD/KOZ | sub-1.5μm | TSV临界尺寸/禁入区 |
| TSV pitch | sub-6μm | TSV间距 |
| Failure rate | <100 ppm | 失效率 |
| Repair rate | 99.9% | 智能冗余修复率 |
| Yield | ~100% with smart redundancy | 近乎100%良率 |
麒麟2026的实测数据
| 指标 | 数值 |
|---|---|
| 晶体管密度 | 155→238 MTr/mm²(单代跃升53.5%) |
| P-Core能效 | +41% |
| 最大频率 | +13%(3.1 GHz) |
| NoC数据通路面积 | -55% |
| SRAM工作频率 | +40%+ |
| 时钟缓冲器数量 | -50% |
| 时钟偏差 | -25% |
| 线长 | -30% |
关键声明:"These gains were achieved at a fixed device node, obtained not through a new lithography step but through a topological reorganization of the spatial distribution of logic in three dimensions."
AI系统层面的τ缩放
论文还阐述了τ-Scaling在AI数据中心中的应用:
| 技术 | 作用 | 效果 |
|---|---|---|
| Unified Bus | 替代PCIe+NVLink+Ethernet的多层协议栈 | 端到端远程访问延迟从几十μs降到~100ns |
| Hi-ONE | 近封装光学引擎,8Tb/s每模块 | SerDes传输距离从 |
| 3D Folding | 将边缘资源迁移到垂直表面 | 解决"N² vs N"的扇出困境 |
开放挑战
何庭波明确列出了六大开放挑战:
- EDA工具链:需要τ-native toolchain——开放的、多物理场的、3D原生的
- 晶圆间工艺变异:键合的晶圆可能来自不同批次,晶圆间变异远大于晶圆内变异
- 垂直互连开销:每个hybrid bond和TSV都有有限的RC代价
- 能耗:τ is a time law, not a joule law.
- 基准测试:需要τ-Profile基准测试
- 经济模型:产业链需要建立新的成本分摊机制
八、韬定律路线图意味着什么?
这张图描绘的是一条"换道领跑"的生存路线:
| 阶段 | 年份 | 密度 | 特征 |
|---|---|---|---|
| 平台期 | 2023-2025 | 126→155 | 工艺微缩陷入停滞 |
| 跃迁期 | 2025-2026 | 155→238 | 逻辑折叠首次商用,+53.5% |
| 缓爬期 | 2026-2030 | 238→292 | 无EUV下的"爬行式微缩",每年+10-15 |
| 再跃迁 | 2030-2031 | 292→400+ | EUV国产化,叠加逻辑折叠 |
斜率的变化直接反映了这一策略的节奏——平台→跃升→缓爬→再跃升。它不是一条平滑的摩尔定律曲线,而是在制裁约束下的"阶梯式突围"路线图。
最大的受益者可能是:中国半导体产业。
台积电可以继续做3nm/2nm,它的最优策略仍是工艺微缩为主。中国大陆晶圆厂被限制在7nm及以下,先进封装几乎是唯一可行的性能突围路径。τ-Scaling提供了一套不需要EUV也能持续进步的方法论。
何庭波论文最后一句话的含义很深:
"The companies, research groups, and ecosystems that adopt τ as the primary objective in the next six to ten years will determine the shape of computing in the decade thereafter."
谁能率先在"非工艺路径"上建立系统优势,谁就可能在后摩尔时代获得定义权。而华为,因为被制裁,恰恰是最早被迫走上这条路的公司之一。
附录:半导体行业小白扫盲
如果你对芯片设计、制造、封测、设备这些概念还有些模糊,下面用"盖房子"的比喻帮你快速理解半导体产业链。
1. 芯片设计——画"设计图纸"
这是芯片诞生的第一步。工程师们决定这枚芯片要用来干什么,并用专门的软件(EDA工具)画出极其精细的电路结构图。最终产出的是一套包含了数十亿甚至上百亿个晶体管连接关系的"设计蓝图"。
就像建筑师和工程师设计出楼房的全部结构、水电布线图纸。
2. 芯片制造——按图"盖房子"
这个环节就是常说的"代工"。工厂拿到设计好的图纸,在纯净的硅片上,通过上千道复杂的工序,把图纸上的电路一层层地雕刻出来。制造完成后是一片晶圆,上面有成千上万个小格子,每个小格子就是一个独立的芯片裸片。
就像施工队拿着图纸,买来钢筋水泥,开始一砖一瓦地把楼房建造起来。
3. 封装与测试——"装修"和"质检"
制造出来的芯片裸片非常脆弱,需要被封装起来。
封装是给裸片穿上保护壳,并连接出金属引脚,让它能方便地焊接到电路板上。测试是对封装好的芯片进行严格的功能和性能测试,筛掉不合格的产品。
就像楼房盖好后,要进行内部装修、通水通电、安装门窗,最后进行竣工验收。
4. 半导体设备——提供"盖楼工具"
上面所有环节都需要用到极其精密的机器。半导体设备公司就是研发和销售这些"工具"的。
关键设备举例:
- 光刻机:像一台超级投影仪,把电路图投影到硅片上。这是最核心、最精密的设备之一。
- 刻蚀机:像一把纳米级的刻刀,把不需要的部分挖掉。
- 薄膜沉积设备:给硅片镀膜,增加新的材料层。
就像为施工队提供高精度的吊车、混凝土泵车、激光测绘仪等重型装备。
总结一下关系
芯片设计公司(如华为海思、高通)画好图纸,交给芯片制造厂(如台积电)去生产。制造厂需要向半导体设备公司(如ASML、应用材料)购买最先进的光刻机等设备来建生产线。生产出来的晶圆再交给封测厂进行封装和测试,最终变成可用的芯片。
先进封装到底是做什么的?
传统封装是给每栋独立的房子装上围墙和门窗,通上水电。
先进封装不再满足于建独立平房,而是建造一个立体、高效、功能复合的摩天大楼。它关注的是如何让楼与楼之间有更宽、更近、更快的道路,共享水电燃气,并高效管理整个社区的交通和热环境。
先进封装的核心目标有三件事:
- 做"超密集的立体交通网":在极短的距离内实现芯片间的高速互联
- 做"异构集成的城市规划":把不同工艺、不同功能的芯片像乐高积木一样组合在一起
- 做"系统级的热管理和结构设计":解决多个高性能芯片紧密堆叠后的散热和应力问题
结语
韬定律的本质很简单:当空间这条路走到头了,就换时间这条路。逻辑折叠就是在芯片上"盖楼",让信号不用横穿整个平面,直接"跳楼"几微米就到。
华为的逻辑折叠在工程上是一项系统性攻坚战。难度大概是这个意思:把两栋都在生火做饭的居民楼无缝粘在一起,让上下楼的水电暖气的压力完全正常,还要保证楼不歪、墙不裂、火灾能控。
它要求材料突破、设备突破、EDA突破、架构突破、工艺突破,缺一不可。
何庭波说"已经解决了关键工程问题",说明华为至少已经全链条上跑通了工艺流程;但距离大规模量产所需的良率和成本目标,可能还需要一到两年的爬坡期。这也是麒麟2026初期可能仅旗舰机型搭载、且产能有限的核心原因。
但无论如何,这条路线已经证明了一件事:有竞争力的性能不再要求永久驻扎在光刻技术的最前沿。在被制裁的至暗时刻,这或许是国产半导体能看到的最亮的一束光。
本文内容基于公开资料和技术分析整理,部分数据引用自华为ISCAS 2026发布内容及何庭波论文《A Time Scaling Theory for Multi-Layer Electronic Systems》。
📎 相关阅读:何庭波论文原文 —— 《A Time Scaling Theory for Multi-Layer Electronic Systems》